国内的小伙伴也可直接查看 hugo-local-search 页面。
近来稍闲,实现了一个 Hugo 本地搜索的小功能,分享一下 ![]() 。
。
简介
让我们先来看一下,它可以做什么吧:
- 内容实时搜索;
- 搜索内容摘要显示;
- 搜索词高亮。
都是一些搜索时常用的功能。稍后,我们来看一下上述功能的一些细节,以及开发过程中的一些糗事 ![]() 。你也可以,先在这里体验一下它的大概使用效果 Search 。
。你也可以,先在这里体验一下它的大概使用效果 Search 。
使用
如何实时获取站点的所有内容呢?这里有两个方面,一就是获取站点的所有页面内容,二是实时获取。
搜索模板页
一个大概的思路,就是创建一个模板页,如 _search.html 文件,利用 Hugo 模板本身的变量(如 .Site)来获取站点所有的页面内容。
<div class="container-search">
<div id="data" style="display: none;">
<!-- 遍历所有的站点页面 -->
{{ range where .Site.Pages "Kind" "section" }}
{{ range .Pages}}
{{ .Title }}%%{{ .Permalink }}%%{{ .Date.Format "2006-01-02" }}%%{{ .Summary }}%%{{ .Content | plainify }}$$$
{{ end }}
{{ end }}
</div>
<!-- 搜索框 -->
<div id="search">
<span class="sc-icon">🔎 </span>
<input id="sc-input" oninput="search()" type="text" placeholder="here search search..." />
<div id="sc-res"></div>
</div>
<!-- 加载所需搜索脚本 -->
<script src="/js/search.js"></script>
</div>
当然,你可以进行按需进行一些修改,过滤掉一些,你不想被搜索到的页面。
下面,我们来看一下核心的 js 搜索脚本 search.js 。其中的注释,是开发过程中帮助记忆和理清思路和一些碎碎念,不要在意。![]()
解析站点页面内容
在 _search.html 模板中,我们分别以 $$$ 来分隔文章,以 %% 来分隔单个页面各部分的信息。
let data = document.querySelector('#data').innerText;
let arr = data.split('$$$');
let map = [];
arr.forEach(item => {
let _arr = item.split('%%');
map.push({
title: _arr[0].trim(), // 标题
permalink: _arr[1], // 链接
date: _arr[2], // 日期
summary: _arr[3], // 摘要
content: item.trim().toLowerCase() // 信息串,包含页面所有信息
})
})
我们把所有的信息都以文本节点的方式,放在元素 #data 中,我们先来解析内容,以得到当前站点所有页面内容的一个集合 map 。
如何搜索
我们的核心就是搜索函数 search() 。在 map 的生成过程中,我们对信息串的 content 做了一些处理,如将所有字符转化为小写。在 search() 中,我们也对搜索词 scVal 进行同样的处理,以实现不区分大小写的内容搜索。
在这之前,我们定义了另一个辅助函数,用来返回搜索词 scVal 在对应页面中出现的所有索引位置 _arrIndex 。
function scanStr(content, str) { // content 页面内容信息串
let index = content.indexOf(str); // str 出现的位置
let num = 0; // str 出现的次数
let arrIndex = []; // str 出现的位置集合
while(index !== -1) {
arrIndex.push(index);
num += 1;
index = content.indexOf(str, index + 1); // 从 str 出现的位置下一位置继续
}
return arrIndex;
}
有它 scanStr 我们就可以方便的知道搜索词都出现在了哪里,以方便后续的内容摘要截取及高亮。
内容摘要截取
通过 scanStr ,我们得到了搜索词在页面内容出现的所有位置,我们默认截取每个位置前后 100 个字符长度(后续我称之后 截取半径)的内容进行罗列展示(可以自定义长度)。这里,我们做了一些小小的优化操作,当后续搜索词的索引位置与当前搜索词的索引位置之差仍小于截取半径的时候,将不再对该位置前后内容进行截取(因为它已经包含在了之前的截取内容中),以避免大量重复性内容的展示。
具体逻辑,还是直接看代码吧,其实不需要了解,因为它并没有什么太大的通用性,都是对字符串的蹂躏和被蹂躏。![]()
let scInput = document.querySelector('#sc-input');
let scRes = document.querySelector('#sc-res')
let scVal = '';
scInput.focus(); // 自动聚集搜索框
function search() {
let post = '';
scVal = scInput.value.trim().toLowerCase();
map.forEach(item => {
if (!scVal) return;
if (item.content.indexOf(scVal) > -1) {
let _arrIndex = scanStr(item.content, scVal);
let strRes = '';
let _radius = 100; // 搜索字符前后截取的长度
let _strStyle0 = '<span style="background: yellow;">'
let _strStyle1 = '</span>'
let _strSeparator = '<hr>'
// 统计与首个与其前邻的索引(不妨称为基准索引)差值小于截取半径的索引位小于截取半径的索引的个数
// 如果差值小于半径,则表示当前索引内容已包括在概要范围内,则不重复截取,且
// 下次比较的索引应继续与基准索引比较,直到大于截取半径, _count重新置 为 0;
let _count = 0;
for (let i = 0, len = _arrIndex.length; i < len; i++) {
let _idxItem = _arrIndex[i];
let _relidx = i;
// 如果相邻搜索词出现的距离小于截取半径,那么忽略后一个出现位置的内容截取(因为已经包含在内了)
if (_relidx > 0 && (_arrIndex[_relidx] - _arrIndex[_relidx - 1 - _count] < _radius)) {
_count += 1;
continue;
}
_count = 0;
// 概要显示
// _startIdx, _endIdx 会在超限时自动归限(默认,无需处理)
strRes += _strSeparator;
let _startIdx = _idxItem - _radius + (_relidx + 1) * _strSeparator.length;
let _endIdx = _idxItem + _radius + (_relidx + 1) * _strSeparator.length;
strRes += item.content.substring(_startIdx, _endIdx);
}
// 进一步对搜索摘要进行处理,高亮搜索词
let _arrStrRes = scanStr(strRes, scVal);
// console.log(_arrStrRes)
for (let i = 0, len = _arrStrRes.length; i < len; i++) {
let _idxItem = _arrStrRes[i];
let _realidx = i;
strRes =
strRes.slice(0, (_idxItem + _realidx * (_strStyle0.length + _strStyle1.length))) + // 当前索引位置之前的部分
_strStyle0 + scVal + _strStyle1 +
strRes.slice(_idxItem + scVal.length + _realidx * (_strStyle0.length + _strStyle1.length)); // 之后的部分
}
post += `
<div class="item" >
<a href="${item.permalink}">
<span>📄</span>
<span class="date">${item.date}</span>
<span>${item.title}</span>
</a>
<div>${strRes}</div>
</div>
`
}
})
let res = `<div class="list">${post}</div>`;
scRes.innerHTML = res;
高亮显示
在遍历获取了所有的搜索摘要 strRes 后,我们需要对其进行进一步的处理,以实现搜索词高亮显示,如下:
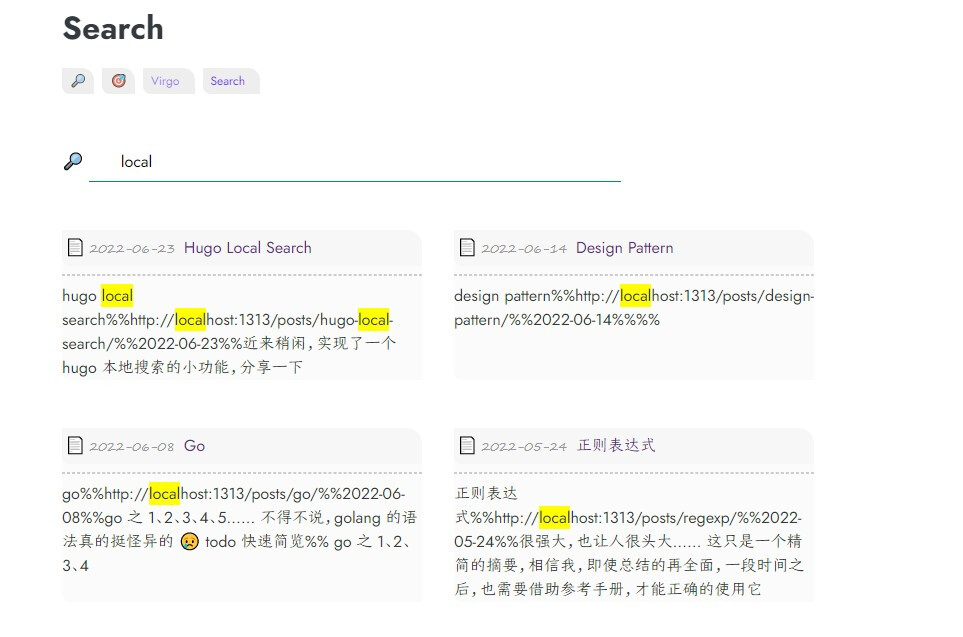
同样,这也是和字符串长度之间的征战,没什么太大意思。
最后
只需要把 search.js 放在 static/js/ 目录下,或者其他你喜欢的路径,但要保证 _search.html 可以正常引用。再使用 Hugo 创建一个对应的 search.md 页面,用来启用 _search.html 模板即可。比如我把 _search.html 模板放在了 single.html 模板中,并且设置只有 /search 路径才加载这部分内容。
{{ $IsSearch := eq .Title "Search"}}
{{ if and .IsPage (not $IsSearch) }}
{{- partial "partials/_prevnext.html" . -}}
{{ end }}
上述代码块中的代码,是完整可用的,复制粘贴即可。